DBN 分类:深度信念网络#
在 RBM 分类的基础上,进一步构建深度信念网络(Deep Belief Network, DBN),通过堆叠多层 RBM 实现更强大的特征学习能力。
目标#
一、RBM 原理概述#
受限玻尔兹曼机(Restricted Boltzmann Machine, RBM)是一种基于能量的概率图模型,由可见层(Visible Layer)和隐层(Hidden Layer)组成,层内无连接,层间全连接。其核心是通过无监督学习学习数据的潜在特征分布。
1. 模型结构#
可见层(``v``):输入数据的显式表示(如像素值)。
隐层(``h``):提取的潜在特征。
权重矩阵(``W``):连接可见层与隐层的权重。
偏置:可见层偏置(
b)和隐层偏置(c)。
2. 能量函数与概率分布#
RBM 的能量函数定义为:
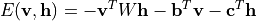
联合概率分布通过玻尔兹曼分布给出:
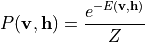
其中 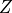 为配分函数(归一化因子)。可见层的边缘分布为:
为配分函数(归一化因子)。可见层的边缘分布为:
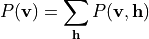
3. 条件独立性#
由于层内无连接,给定可见层时隐层条件独立,反之亦然:
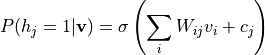
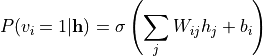
其中 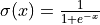 为 Sigmoid 激活函数。
为 Sigmoid 激活函数。
4. 训练目标#
通过最大化似然函数学习参数(W, b, c)。目标函数为负对数似然:
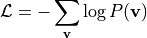
采用对比散度(CD)算法近似梯度,更新规则为:
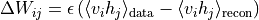
其中  为学习率,
为学习率,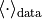 和
和 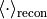 分别为数据分布和重构分布的期望。
分别为数据分布和重构分布的期望。
二、整体模块架构与训练模式#
代码实现了基于 PyTorch 的深度信念网络(DBN),采用分层架构设计,支持从无监督预训练到有监督学习的完整流程。
模块架构:
``DBNPretrainer`` 实现多层 RBM 的堆叠与逐层无监督预训练,提供特征提取接口。
``AbstractSupervisedDBN`` 定义 DBN 监督学习的通用接口,用于支持多模式训练策略,包括预训练、微调、分类器训练与预测等抽象方法。
``AbstractSupervisedDBNClassifier`` 基于
AbstractSupervisedDBN,实现 PyTorch 下的通用工具方法封装,包括特征提取、分类器集成(逻辑回归、支持向量机以及随机森林等)。``SupervisedDBNClassification`` 具体分类任务实现、微调网络构建以及训练。
训练模式:
无监督模式:仅预训练,用于特征提取。
分类器模式:预训练 + 下游分类器训练。
微调网络模式:预训练 + 网络反向传播微调。
三、核心类功能和接口概述#
1. DBNPretrainer 无监督训练DBN#
关键参数:
hidden_layers_structure:隐层单元数(默认两层[100, 100])learning_rate_rbm:RBM 学习率(默认 0.1)n_epochs_rbm:每层 RBM 训练轮数(默认 10)batch_size:批大小(默认 100)verbose:打印训练信息(默认 True)shuffle:数据打乱(默认 True)drop_last:是否丢弃最后不足 batch 的样本(默认 False)random_state:随机种子
设备支持:自动选择 GPU(
cuda)或 CPU核心方法:
创建 RBM 层(``create_rbm_layer`` 方法) 初始化 RBM:使用
RestrictedBoltzmannMachine定义可见层与隐层维度。单批次训练步骤(``_train_batch`` 方法)
正相(Positive Phase):计算隐层激活概率
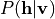 。
。负相(Negative Phase):通过模拟退火采样器(
SimulatedAnnealingOptimizer)生成重构样本。目标函数:最小化能量函数加权重衰减(L2 正则化)。
反向传播:更新权重和偏置。
单层 RBM 训练(``_train_rbm_layer`` 方法) - 初始化优化器:采用随机梯度下降(SGD)优化参数。 - DataLoader 处理批量数据。
预训练堆叠 RBM(``fit`` 方法)
特征变换,逐层提取特征(``transform`` 方法)
2. AbstractSupervisedDBN 抽象接口定义#
关键参数:
fine_tuning:模式选择(默认 False)learning_rate:微调学习率(默认 0.1)n_iter_backprop:反向传播迭代次数(默认 100)l2_regularization:L2 正则化(默认 1e-4)activation_function:激活函数(默认'sigmoid')dropout_p:Dropout 概率(默认 0.0)
3. AbstractSupervisedDBNClassifier 分类器模式具体实现,以及微调网络构建工具#
关键参数:
classifier_type:支持多种分类器(默认逻辑回归)clf_C:正则化强度(默认 1.0)clf_iter:迭代次数(默认 100)
4. SupervisedDBNClassification 具体分类实现#
微调网络构建:使用预训练的权重来初始化(默认两层 RBM,以及无 Dropout 层)
网络结构:输入层 → [线性层 + 激活函数 + Dropout] × N → 输出层
线性层:使用对应的 RBM 的权重初始化
输出层:随机初始化,在微调阶段学习
训练策略:
使用预训练权重初始化
CrossEntropyLoss损失函数SGD 优化器 + L2 正则化
支持 Dropout 防止过拟合
5. 其他内容#
数据加载(``load_data`` 方法)
数据集:使用
sklearn.datasets.load_digits(8×8 手写数字图像)。增强:对原始图像进行上下左右平移,扩展数据集。
训练过程可视化(``_visualize_training_progress`` 方法,设置 ``plot_img=True``)
权重与梯度:实时监控权重矩阵及其梯度变化。
生成样本:实时展示模型“生成”新样本的能力。
重建样本:可视化重建误差的演变。
结果可视化(``RBMVisualizer`` 类)
训练后 RBM 权重可视化
分类任务结果:混淆矩阵可视化
重建样本:训练完成后对测试图像进行编码-解码得到的重建