预备知识#
受限玻尔兹曼机(Restricted Boltzmann Machine)是一种基于能量的概率图模型,由可见层(Visible Layer)和隐层(Hidden Layer)组成,层内无连接,层间全连接。 其核心是通过无监督学习学习数据的潜在特征分布。
1. 神经网络基础#
1.1 神经元模型#
人工神经元是神经网络的基本计算单元。给定输入向量 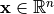 ,其输出为:
,其输出为:
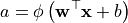
其中 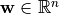 为权重向量,
为权重向量,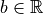 为偏置项,
为偏置项,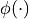 为激活函数。在概率生成模型中,常用 Sigmoid 激活函数:
为激活函数。在概率生成模型中,常用 Sigmoid 激活函数:
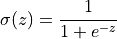
1.2 基于能量的模型#
与前馈网络不同,能量基模型(Energy-Based Models, EBMs)通过一个标量能量函数 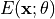 定义数据的概率分布:
定义数据的概率分布:
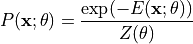
其中配分函数(partition function):
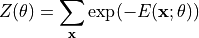
确保概率归一化。低能量状态对应高概率。
2. 玻尔兹曼机结构#
可见层(v):输入数据的显式表示(如像素值)。
隐藏层(h):提取的潜在特征。
权重矩阵(w):连接可见层与隐层的权重。
偏置:可见层偏置(b)和隐层偏置(c)。
玻尔兹曼机(BM)的拓扑结构是全连接的,而受限玻尔兹曼机通过去掉了可见层和隐藏层内部的链接, 让Gibbs采样的过程更加高效。
由于 RBM 的受限结构,隐变量在给定可见变量时相互独立,其条件概率为:
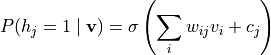
同理,
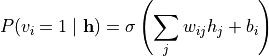
3. 能量函数与概率分布#
3.1 能量函数#
RBM 的能量函数定义为:
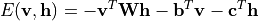
其中,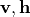 分别是可见层和隐层的状态,
分别是可见层和隐层的状态,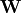 是连接的权重,
是连接的权重,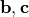 是一次项系数。
是一次项系数。
联合概率分布通过玻尔兹曼分布给出:
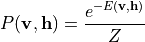
其中 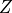 为配分函数(归一化因子)。可见层的边缘分布为:
为配分函数(归一化因子)。可见层的边缘分布为:
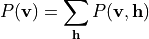
通过最大化似然函数学习参数 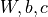 。目标函数为负对数似然:
。目标函数为负对数似然:
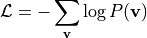
采用对比散度(CD)算法近似梯度,更新规则为:
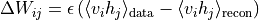
其中  为学习率,
为学习率,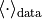 和
和 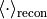 分别为数据分布和重构分布的期望。
分别为数据分布和重构分布的期望。
3.2 梯度的推导#
能量模型的概率可以写成:
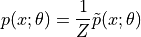
其梯度为:
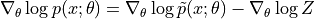
配分函数的梯度难以直接计算
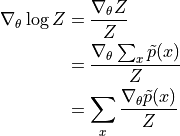
对于保证所有的 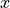 都有
都有  的模型,我们可以用
的模型,我们可以用 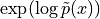 代替
代替 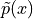 。
。
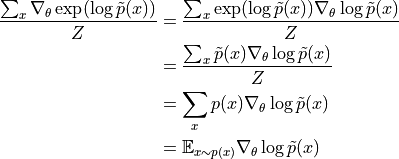
综上,
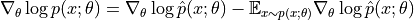
第二项中 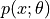 实际上是模型预测的
实际上是模型预测的 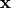 的分布,而训练中的第一项是服从实际的数据的分布的。即上式可以写成
的分布,而训练中的第一项是服从实际的数据的分布的。即上式可以写成
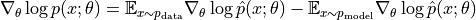
这里我们考虑玻尔兹曼机的能量函数,容易求得
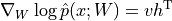
只要分别得到 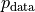 ,
, 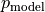 分布下的
分布下的  和
和 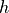 的值即可计算梯度。即为:
的值即可计算梯度。即为: