Q-VAE:量子变分自编码器#
本教程演示如何训练和评估量子变分自编码器(Quantum Variational Autoencoder, Q-VAE)模型。Q-VAE 结合了变分自编码器和量子玻尔兹曼机,能够实现更强大的生成和表征学习能力。
目标#
理解 Q-VAE 的架构和工作原理
在 MNIST 数据集上训练 Q-VAE
进行图像重建和生成
使用 Q-VAE 进行表征学习和分类
使用 t-SNE 可视化潜在空间
运行环境#
示例位置: example/qvae_mnist/
train_qvae.ipynb: 训练 Q-VAE 模型train_qvae_classifier.ipynb: 表征学习与分类
依赖项:
pip install torchvision==0.22.0 torchmetrics[image]
1、QVAE 原理概括#
QVAE(Quantum Variational Autoencoder)是一种将 量子生成模型 引入 变分自编码器 (VAE) 潜空间的生成模型。其核心思想是:
> 用量子玻尔兹曼机(QBM)替代传统 VAE 中的先验分布,从而构建一个具有量子生成能力的潜变量模型。
模型结构#
QVAE 包括以下关键组件:
编码器(Encoder) 将输入数据
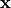 映射为潜变量的近似后验分布
映射为潜变量的近似后验分布
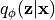 ,通常由神经网络参数化。
,通常由神经网络参数化。先验分布(Prior) 使用 量子玻尔兹曼机 (QBM) 建模潜变量
 的先验分布。哈密顿量为:
的先验分布。哈密顿量为: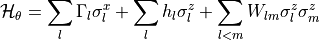
解码器(Decoder) 将潜变量
(或其连续松弛变量 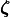 )映射回数据空间,并使用解码器重建原始数据:
)映射回数据空间,并使用解码器重建原始数据:
训练目标:Q-ELBO#
QVAE 使用一个 量子下界 (Q-ELBO) 来近似最大化对数似然:
![\mathcal{L}_{\text{Q-ELBO}} = \mathbb{E}_{q_\phi(\mathbf{z}|\mathbf{x})} [\log p_\theta(\mathbf{x} | \boldsymbol{\zeta})] - \tilde{H}(q_\phi(\mathbf{z}|\mathbf{x}) \| p_\theta(\mathbf{z}))](../../../_images/math/0c6dbe385c93ea97dd7f92083f3161a12210fbb6.png)
QBM 采样与训练#
正相(positive phase):从编码器采样
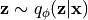
负相(negative phase):从 QBM 中采样
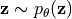 ,使用 蒙特卡洛方法 或 量子退火器
,使用 蒙特卡洛方法 或 量子退火器
把能量作为目标函数,objective 的梯度即为基于正相和负相采样计算的梯度。
2. 模型架构#
定义了用于自编码器架构的 Encoder 和 Decoder 两个模块,均继承自 nn.Module。
两者结构对称:包含一个全连接层、层归一化(LayerNorm)和双曲正切激活函数,并支持通过 L2 权重衰减进行正则化。
编码器将高维输入映射到低维潜在空间,而解码器尝试从潜在表示重构原始输入。
每个模块提供 get_weight_decay 方法,用于在训练损失中显式加入权重正则项,以提升模型泛化能力并防止过拟合。
2.1 编码器#
class Encoder(nn.Module):
def __init__(
self,
input_dim: int,
hidden_dim: int,
latent_dim: int,
weight_decay: float = 0.01,
) -> None:
super().__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.latent_dim = latent_dim
self.weight_decay = weight_decay
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.norm1 = nn.LayerNorm(hidden_dim)
self.fc2 = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
x = self.fc1(x)
x = self.norm1(x)
x = F.tanh(x)
x = self.fc2(x)
return x
def get_weight_decay(self) -> torch.Tensor:
"""计算权重的L2正则化损失
对权重矩阵施加L2正则化可以提高模型的泛化能力。
Returns:
torch.Tensor: L2正则化损失值
"""
return self.weight_decay * (
torch.sum(self.fc1.weight**2) + torch.sum(self.fc2.weight**2)
)
2.2 解码器#
class Decoder(nn.Module):
def __init__(
self,
input_dim: int,
hidden_dim: int,
latent_dim: int,
weight_decay: float = 0.01,
) -> None:
super().__init__()
self.input_dim = input_dim
self.hidden_dim = hidden_dim
self.latent_dim = latent_dim
self.weight_decay = weight_decay
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.norm1 = nn.LayerNorm(hidden_dim)
self.fc2 = nn.Linear(hidden_dim, latent_dim)
def forward(self, z):
z = self.fc1(z)
z = self.norm1(z)
z = F.tanh(z)
z = self.fc2(z)
return z
def get_weight_decay(self) -> torch.Tensor:
"""计算权重的L2正则化损失
对权重矩阵施加L2正则化可以提高模型的泛化能力。
Returns:
torch.Tensor: L2正则化损失值
"""
return self.weight_decay * (
torch.sum(self.fc1.weight**2) + torch.sum(self.fc2.weight**2)
)
2.3 Q-VAE 完整模型#
参考模块手册中的QVAE类。
3. 数据准备#
该函数封装了 MNIST 数据集的加载与预处理流程,返回训练和测试用的 DataLoader。
数据通过 ToTensor 转换为张量,并利用自定义的 flatten_tensor 将 28×28 图像展平为 784 维向量,适配全连接网络输入。
训练加载器启用打乱(shuffle),而测试加载器保持顺序以确保评估一致性。
def setup_data_loaders(root, download=True, batch_size=256, use_cuda=False):
"""
设置MNIST数据集的数据加载器
Args:
root (str): 数据存储根目录
download (bool): 如果数据不存在是否下载,默认为True
batch_size (int): 每个批次的样本数量,默认为128
use_cuda (bool): 是否使用GPU,决定是否启用pin_memory优化
Returns:
tuple: (train_loader, test_loader) 训练和测试数据加载器
"""
# 数据预处理
transform = transforms.Compose([
transforms.ToTensor(), # 转换为Tensor
transforms.Lambda(flatten_tensor) # 展平:将28x28图像展平成784维向量
# 等效于:x.reshape(-1) 或 x.flatten()
])
# 加载训练集
train_set = datasets.MNIST(
root=root, # 数据存储路径
train=True, # 加载训练集(共60000个样本)
transform=transform, # 应用定义的数据变换
download=download # 如果数据不存在则自动下载
)
# 加载测试集
test_set = datasets.MNIST(
root=root, # 数据存储路径
train=False, # 加载测试集(共10000个样本)
transform=transform # 应用相同的数据变换
)
# 数据加载器配置参数
# 根据是否使用GPU选择不同的优化参数
# 将num_workers设为0避免多进程问题
kwargs = {'num_workers': 0, 'pin_memory': True} if use_cuda else {'num_workers': 0}
# 创建训练数据加载器
train_loader = DataLoader(
dataset=train_set, # 训练数据集
batch_size=batch_size, # 每个批次的样本数
shuffle=True, # 每个epoch打乱数据顺序,防止模型记忆顺序
**kwargs # 解包上述配置参数
)
# 创建测试数据加载器
test_loader = DataLoader(
dataset=test_set, # 测试数据集
batch_size=batch_size, # 批次大小(通常与训练集相同)
shuffle=False, # 测试集不需要打乱,保证可重复性
**kwargs # 解包配置参数
)
return train_loader, test_loader
4. 模型训练#
该函数实现了量子变分自编码器(Q-VAE)在 MNIST 数据集上的完整训练流程。 模型结合了经典神经网络编码器/解码器与受限玻尔兹曼机(RBM),通过最小化带权重衰减的负 ELBO 损失进行优化,并引入 KL 散度控制潜在分布与先验的对齐程度。 训练过程中记录各项损失指标并定期保存至文件。
def train_qvae(
train_loader, # 用于训练QVAE
device,
input_dim=784, # 图片拉伸后的维度
hidden_dim=512, # fc1压缩后的维度
latent_dim=256, # 隐变量维度, num_visible + num_hidden
num_var1=128, # RBM可见层维度
num_var2=128, # RBM藏层维度
dist_beta=10, # 重叠分布的beta
weight_decay=0.01,
batch_size=256,
epochs=20,
lr=1e-3,
kl_beta=0.000001,
save_path="./models/",
sampler_type="sa",
):
# 创建模型
model, optimizer = create_model(
train_loader,
input_dim=input_dim,
hidden_dim=hidden_dim,
latent_dim=latent_dim,
weight_decay=weight_decay,
dist_beta=dist_beta,
num_var1=num_var1,
num_var2=num_var2,
lr=lr,
device=device,
sampler_type=sampler_type,
)
# 训练循环
loss_history = []
elbo_history = []
kl_history = []
cost_history = []
model.train() # 设置模型为训练模式
for epoch in tqdm(range(1, epochs + 1), desc="Training QVAE"): # 遍历每个训练轮次
# 训练一个epoch
avg_loss, avg_elbo, avg_kl, avg_cost = _train_epoch(
model, train_loader, optimizer, kl_beta, device
)
# 记录历史指标
loss_history.append(avg_loss)
elbo_history.append(avg_elbo)
kl_history.append(avg_kl)
cost_history.append(avg_cost)
save_list_to_txt(os.path.join(save_path, "loss_history.txt"), loss_history)
save_list_to_txt(os.path.join(save_path, "elbo_history.txt"), elbo_history)
save_list_to_txt(os.path.join(save_path, "cost_history.txt"), cost_history)
save_list_to_txt(os.path.join(save_path, "kl_history.txt"), kl_history)
# # 保存当前轮次的模型参数
# model_save_path = os.path.join(save_path, f'davepp_epoch{epoch}.pth')
# torch.save(model.state_dict(), model_save_path)
# 打印本轮训练结果
print(
f"Epoch {epoch}/{epochs}: "
f"Loss: {avg_loss:.4f}, "
f"elbo: {avg_elbo:.4f}, "
f"KL: {avg_kl:.4f}, "
f"Cost: {avg_cost:.4f}"
)
# 保存模型
model_save_path = os.path.join(save_path, f"qvae_mnist.pth")
torch.save(model.state_dict(), model_save_path)
return model
5. 可视化与评估#
本节提供两类关键可视化工具:
一是通过 plot_training_curves 绘制训练/验证损失与准确率曲线,用于监控模型收敛情况;
二是利用 t_SNE 对 QVAE 模型提取的潜在表示进行降维可视化,揭示不同类别在隐空间中的分布结构。
两者均支持自动保存高分辨率图像,并可灵活控制是否实时显示,便于实验分析、结果记录。
5.1 训练过程可视化#
def plot_training_curves(
train_loss_history,
val_loss_history,
train_acc_history,
val_acc_history,
save_path=None,
show=True,
):
"""
绘制训练和验证的损失及准确率曲线
Args:
train_loss_history: 训练损失历史
val_loss_history: 验证损失历史
train_acc_history: 训练准确率历史
val_acc_history: 验证准确率历史
save_path: 图像保存路径
"""
plt.figure(figsize=(12, 5))
# 损失曲线
plt.subplot(1, 2, 1)
plt.plot(train_loss_history, label="Training Loss", color="blue", alpha=0.7)
plt.plot(val_loss_history, label="Validation Loss", color="red", alpha=0.7)
plt.title("Training and Validation Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.grid(True, alpha=0.3)
# 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(train_acc_history, label="Training Accuracy", color="blue", alpha=0.7)
plt.plot(val_acc_history, label="Validation Accuracy", color="red", alpha=0.7)
plt.title("Training and Validation Accuracy")
plt.xlabel("Epoch")
plt.ylabel("Accuracy (%)")
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
# plt.close()
# 自动保存
if save_path is None:
# 生成默认保存路径
# timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
save_path = f"results/mlp_training_curves_{timestamp}.png"
plt.savefig(save_path, dpi=300, bbox_inches="tight")
print(f"Training curves saved to: {save_path}")
plt.show()
if show:
plt.show()
else:
plt.close() # 不显示时关闭图像,节省内存
5.3 潜在空间可视化#
def t_SNE(
test_loader,
qvae_model,
use_std=True,
point_size=20,
alpha=0.6,
epochs=None,
save_path=None,
show=True,
):
"""
QVAE版本的t-SNE可视化
Args:
test_loader: 测试数据加载器
qvae_model: QVAE模型
use_std: 是否使用标准差
point_size: 点大小
alpha: 透明度
epochs: 训练轮数
save_path: 保存路径
show: 是否显示图像
"""
features = []
labels = []
qvae_model.eval()
device = next(qvae_model.parameters()).device
with torch.no_grad():
for batch_idx, (example_data, example_targets) in enumerate(test_loader):
example_data = example_data.to(device)
# QVAE前向传播 - 获取潜变量zeta
_, _, _, zeta = qvae_model(example_data)
zeta_np = zeta.cpu().numpy()
for idx in range(zeta_np.shape[0]):
features.append(zeta_np[idx])
labels.append(example_targets[idx].item())
# 创建DataFrame
feat_cols = [f"dim_{i}" for i in range(zeta_np.shape[1])]
df = pd.DataFrame(features, columns=feat_cols)
df["label"] = labels
df["label"] = df["label"].apply(lambda i: str(i))
print(f"Extracted {len(features)} samples with {zeta_np.shape[1]} dimensions")
# 执行t-SNE
print("Running t-SNE...")
tsne = TSNE(n_components=2, verbose=1, perplexity=30, max_iter=300, random_state=42)
tsne_results = tsne.fit_transform(df[feat_cols].values)
df_tsne = df.copy()
df_tsne["x-tsne"] = tsne_results[:, 0]
df_tsne["y-tsne"] = tsne_results[:, 1]
# 可视化
# plt.figure(figsize=(10, 8))
# scatter = plt.scatter(df_tsne['x-tsne'], df_tsne['y-tsne'],
# c=df_tsne['label'].astype(int),
# cmap='tab10', s=point_size, alpha=alpha)
fig, ax = plt.subplots(figsize=(10, 8))
scatter = ax.scatter(
df_tsne["x-tsne"],
df_tsne["y-tsne"],
c=df_tsne["label"].astype(int),
cmap="tab10",
s=point_size,
alpha=alpha,
)
# 添加颜色条
cbar = plt.colorbar(scatter, ax=ax, label="Digit")
# 动态标题和文件名
training_status = "fully_trained" if epochs and epochs >= 20 else f"epochs_{epochs}"
title = f"t-SNE Visualization of QVAE Latent Space ({training_status})"
plt.title(title)
plt.xlabel("t-SNE dimension 1")
plt.ylabel("t-SNE dimension 2")
plt.tight_layout()
# 自动保存
if save_path is None:
# 生成默认保存路径
# timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
timestamp = datetime.datetime.now().strftime("%Y%m%d_%H%M%S")
save_path = f"results/t-SNE_QVAE_{training_status}_{timestamp}.png"
plt.savefig(save_path, dpi=300, bbox_inches="tight")
print(f"t-SNE plot saved to: {save_path}")
plt.show()
if show:
plt.show()
else:
plt.close() # 不显示时关闭图像,节省内存
return df_tsne, save_path, training_status
6. 表征学习与分类#
Q-VAE 学到的表征可用于下游分类任务:
该函数 train_mlp_classifier 用于训练一个多层感知机(MLP)分类器,输入特征是通过QVAE模型提取的数据表征。
它首先将数据集划分为训练集和验证集,并初始化一个MLP模型、优化器和损失函数。
在每个训练周期,模型参数根据训练集更新,并在验证集上评估性能。
def train_mlp_classifier(
features,
labels,
device,
epochs=100,
lr=1e-3,
weight_decay=1e-4,
batch_size=64,
seed=42,
smoke_test=False,
show=True,
save_path="./models/",
):
# 数据分割
X_train, X_val, y_train, y_val = train_test_split(
features.numpy(), labels.numpy(), test_size=0.4, random_state=seed
)
X_train = torch.FloatTensor(X_train)
y_train = torch.LongTensor(y_train)
X_val = torch.FloatTensor(X_val)
y_val = torch.LongTensor(y_val)
train_dataset = TensorDataset(X_train, y_train)
val_dataset = TensorDataset(X_val, y_val)
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_loader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# MLP模型
mlp = MLP(input_dim=features.shape[1], output_dim=10).to(device)
optimizer = torch.optim.Adam(mlp.parameters(), lr=lr, weight_decay=weight_decay)
criterion = nn.CrossEntropyLoss()
# 记录训练历史
train_loss_history = []
val_loss_history = []
train_acc_history = []
val_acc_history = []
# 训练循环
best_acc = 0
for epoch in tqdm(range(1, epochs + 1), desc="Training MLP"):
# 训练阶段
train_acc, avg_train_loss = _train_mlp_epoch(
model=mlp,
data_loader=train_loader,
optimizer=optimizer,
criterion=criterion,
device=device,
)
# 验证阶段
val_acc, avg_val_loss = _eval_mlp_epoch(
model=mlp, data_loader=val_loader, criterion=criterion, device=device
)
# 记录历史
train_loss_history.append(avg_train_loss)
val_loss_history.append(avg_val_loss)
train_acc_history.append(train_acc)
val_acc_history.append(val_acc)
# 打印训练和验证指标
if epoch % 5 == 0:
print(
f"Epoch {epoch:3d}: "
f"Train Loss: {avg_train_loss:.4f}, "
f"Val Loss: {avg_val_loss:.4f}, " # 新增验证损失
f"Train Acc: {train_acc:.2f}%, "
f"Val Acc: {val_acc:.2f}%"
)
if val_acc > best_acc:
best_acc = val_acc
model_save_path = os.path.join(save_path, "best_mlp_classifier.pth")
torch.save(mlp.state_dict(), model_save_path)
print(f"Best Validation Accuracy: {best_acc:.2f}%")
# 绘制训练曲线
curves_save_path = ""
if not smoke_test:
curves_save_path = os.path.join(
save_path, f"mlp_training_curves_epochs_{epochs}.png"
)
plot_training_curves(
train_loss_history=train_loss_history,
val_loss_history=val_loss_history,
train_acc_history=train_acc_history,
val_acc_history=val_acc_history,
save_path=curves_save_path,
show=show,
)
return mlp, best_acc, curves_save_path
7. 科研应用:QBM-VAE#
Q-VAE 的进阶版本 QBM-VAE 在科研中展示了重要价值:
单细胞转录组学分析:
显著提升聚类精度
检测传统方法无法辨识的新型细胞亚型
为靶点发现提供新线索