BM 生成:玻尔兹曼机数据生成#
本教程演示如何使用全连接玻尔兹曼机(Boltzmann Machine, BM)进行无监督训练和数据生成。该方法适合快速生成大量小规模样本的场景。
目标#
理解全连接玻尔兹曼机与受限玻尔兹曼机的区别
使用 KL 散度和对比散度训练 BM
实现学习率调度和采样策略
可视化生成样本的分布
运行环境#
示例位置: example/bm_generation/
train_bm.ipynb: 训练代码sample_bm.ipynb: 采样和测试代码
依赖项:
pip install kaiwu==1.3.0 pandas matplotlib
1. 全连接玻尔兹曼机简介#
1.1 BM vs RBM#
特性 |
受限玻尔兹曼机(RBM) |
全连接玻尔兹曼机(BM) |
|---|---|---|
连接结构 |
层间全连接,层内无连接 |
所有节点全连接 |
采样方式 |
可并行采样 |
需要顺序采样 |
训练效率 |
较高 |
较低 |
表达能力 |
受限于双分图结构 |
更强,可建模任意分布 |
1.2 适用场景#
全连接玻尔兹曼机适用于:
需要建模复杂依赖关系的场景
小规模样本生成
研究玻尔兹曼分布采样问题
1.3 数据生成流程#
负相采样 调用
self.bm_net.sample(self.worker)从当前 BM 的联合分布中生成一组完整的可见-隐含状态样本state_all,用于近似模型分布以计算对比散度类目标。正相采样 对每个输入批次
data,执行两类正相采样:完整条件采样:以完整输入
data为可见层固定值,采样对应的完整状态state_v。部分条件采样:仅固定输入的非输出部分(即
data[:, :-num_output]),对输出维度进行自由采样,得到state_vi。
这两类采样分别用于计算:
KL 散度项(kl_divergence):衡量模型分布与数据分布的差异。
负条件似然项(ncl):鼓励模型在给定输入条件下正确重建输出部分。
目标函数构建 最终优化目标为加权组合:
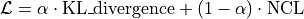
其中
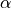 由
由 cost_param["alpha"]控制,平衡生成能力与条件一致性。多进程加速 将一个 batch 的数据按进程数切分,每个子进程独立调用
process_solve_graph执行正相采样与概率估计,结果合并后用于梯度计算。
1.4 数据生成特点#
支持条件生成:可指定部分可见单元为观测值,其余单元由模型生成,适用于半监督或序列补全任务。
可微分训练:所有采样操作嵌入 PyTorch 计算图,支持端到端反向传播。
可视化支持:训练过程中可实时绘制权重矩阵及其梯度,便于调试与分析。
灵活输出结构:通过
num_output参数显式区分“输入”与“输出”可见单元,适配回归/分类等监督设定。
2. 加载数据#
CSVDataset 是一个继承自 PyTorch Dataset 的轻量级数据集封装类,
用于加载以 NumPy 数组或列表形式存储的结构化数据(如从 CSV 文件读取的数据)。
该类实现了 __len__ 和 __getitem__ 方法,使其可与 DataLoader 无缝配合使用。
每次通过索引访问样本时,会自动将数据转换为 torch.float32 类型的张量,确保与神经网络模型的输入要求一致。
此类适用于无标签的自监督学习任务或作为通用数据加载器的基础组件。
class CSVDataset(Dataset):
"""
数据集
Args:
data: 输入数据,形状为 (numcol, numrow)
"""
def __init__(self, data):
self.data = data
def __len__(self):
"""
返回数据集的大小
"""
return len(self.data)
def __getitem__(self, idx):
"""
根据索引获取数据
Args:
idx: 索引
Return:
torch.Tensor: 数据
"""
return torch.tensor(self.data[idx], dtype=torch.float32)
3. 模型构建#
该初始化方法用于配置一个基于玻尔兹曼机的训练框架。它接收输入数据、结果保存器( saver )和任务处理器( worker ),
并设定可见层、隐层与输出层的节点数量。内部构建了一个总节点数为可见层与隐层之和的玻尔兹曼网络(BoltzmannMachine),并初始化了学习相关的超参数,
包括动量项和正则化系数( alpha 与 beta)。
此结构为后续的能量建模、采样训练及模型评估提供了基础支撑,适用于无监督或生成式学习任务。
def __init__(
self, data, saver, worker, num_visible=100, num_hidden=10, num_output=10
):
"""初始化 Trainer。
Args:
data (list): 训练数据列表,每个元素应为 torch.Tensor。
saver (object): 具备 save_info 和 output_loss 方法的持久化对象。
worker (object): 执行采样的后端 worker。
num_visible (int): 可见层维数。默认为 100。
num_hidden (int): 隐藏层维数。默认为 10。
num_output (int): 输出层维数。默认为 10。
"""
self.data = data
self.saver = saver
self.worker = worker
self.num_visible = num_visible
self.num_hidden = num_hidden
self.num_output = num_output
self.learning_parameters = {
"learning_rate": 0.001,
"weight_decay_rate": 0.0,
"momentum_rate": 0.0,
}
self.bm_net = BoltzmannMachine(num_nodes=self.num_visible + self.num_hidden)
# 核心:将模型参数移动到共享内存中,供多进程直接访问
if self.bm_net.device.type != "cpu":
self.bm_net_cpu = BoltzmannMachine(
num_nodes=self.num_visible + self.num_hidden
).to(torch.device("cpu"))
else:
self.bm_net_cpu = self.bm_net
self.bm_net_cpu.share_memory()
self.cost_param = {"alpha": 0.5, "beta": 0.5}
4. 训练流程#
4.1 学习率调度器#
CosineScheduleWithWarmup 是一个自定义的学习率调度器,继承自 PyTorch 的 LambdaLR。
它在训练初期采用线性 warmup 策略逐步提升学习率,随后应用余弦退火策略平滑地衰减学习率至零。
该调度方式有助于模型在初始阶段稳定收敛,并在后期精细调整参数,广泛应用于深度学习任务中以提升训练效果和泛化能力。 用户可灵活配置 warmup 步数、总训练步数及余弦周期数。
class CosineScheduleWithWarmup(LambdaLR):
"""带有warmup的余弦退火学习率调度器"""
def __init__(
self,
optimizer,
num_warmup_steps,
num_training_steps,
num_cycles=0.5,
last_epoch=-1,
):
self.num_warmup_steps = num_warmup_steps
self.num_training_steps = num_training_steps
self.num_cycles = num_cycles
super(CosineScheduleWithWarmup, self).__init__(
optimizer, self.lr_lambda, last_epoch
)
def lr_lambda(self, current_step):
"""带有warmup的cosine schedule学习率生成器"""
if current_step < self.num_warmup_steps:
return float(current_step) / float(max(1, self.num_warmup_steps))
descent_steps = float(max(1, self.num_training_steps - self.num_warmup_steps))
progress = float(current_step - self.num_warmup_steps) / descent_steps
return max(
0.0,
0.5 * (1.0 + math.cos(math.pi * float(self.num_cycles) * 2.0 * progress)),
)
4.2 训练器实现#
该训练方法实现了基于玻尔兹曼机的自定义优化过程,结合了 KL 散度与负对比似然(NCL)的混合损失函数。
训练中使用 Adam 优化器,并配合带 warmup 的余弦退火学习率调度器以提升收敛稳定性。 每一步通过采样生成全局状态,并利用多进程并行处理子任务以加速计算。损失值定期输出,模型参数和训练信息每隔若干步保存一次。 此外,还支持可视化权重及其梯度,便于调试与分析训练动态。
def train(self, max_steps, save_path, num_processes=1):
"""执行模型训练主循环。
通过多进程并行采样并结合 Adam 优化器更新玻尔兹曼机参数。
Args:
max_steps (int): 最大训练步数。
save_path (str): 模型和日志的保存路径。
num_processes (int): 并行采样的进程数。默认为 1。
"""
optimizer = torch.optim.Adam(
self.bm_net.parameters(),
lr=self.learning_parameters["learning_rate"],
weight_decay=self.learning_parameters["weight_decay_rate"],
)
scheduler = CosineScheduleWithWarmup(
optimizer,
num_training_steps=max_steps,
num_warmup_steps=int(max_steps / 20),
num_cycles=0.5,
)
t_start = time.time()
step = 0
self.saver.save_info(self.bm_net, save_path, 0, 0.0)
# 预先分配 Pool 以减少重复创建开销
pool = mp.Pool(processes=num_processes)
while step < max_steps:
for batch_data in self.data:
if step >= max_steps:
break
optimizer.zero_grad()
step += 1
# 1. 负相位采样 (从当前模型分布采样)
# 这个步骤通常对整个模型进行,直接由主进程执行
state_all = self.bm_net.sample(self.worker).detach()
# 2. 多进程并行正相位采样 (共享存储模式)
# 将本批次数据设为共享内存
self._sync_gpu_to_cpu()
cpu_data = batch_data.cpu().share_memory_()
# 按进程数切分数据
chunks = torch.chunk(cpu_data, num_processes)
# 准备子进程参数 (传递共享的模型对象)
sd_args = [
(self.bm_net_cpu, self.worker, chunk, self.num_output)
for chunk in chunks
if chunk.size(0) > 0
]
# 并行执行采样
all_results = pool.map(process_solve_graph_worker, sd_args)
# 3. 汇总结果并计算 Loss
kl_divergence = torch.tensor(0.0, device=state_all.device)
ncl = torch.tensor(0.0, device=state_all.device)
# 收集所有进程的采样状态
combined_v = torch.cat([res[0] for res in all_results], dim=0).to(
self.bm_net.device
)
combined_vi = torch.cat([res[1] for res in all_results], dim=0).to(
self.bm_net.device
)
# 计算 KL 散度项
kl_divergence = self.bm_net.objective(combined_v, state_all)
# 计算 NCL (Non-Contrastive Loss) 类似项
# 保持原逻辑:将输出部分置零后计算 objective
v_ncl = combined_v.clone()
vi_ncl = combined_vi.clone()
v_ncl[:, -self.num_output :] = 0.0
vi_ncl[:, -self.num_output :] = 0.0
ncl = self.bm_net.objective(v_ncl, vi_ncl)
# 组合目标函数
obj = (
self.cost_param["alpha"] * kl_divergence
+ (1 - self.cost_param["alpha"]) * ncl
)
# 4. 反向传播与优化
obj.backward()
# 可视化 (保留原逻辑)
if step % 10 == 0:
plt.figure(figsize=(8, 4))
plt.subplot(1, 2, 1)
plt.imshow(self.bm_net.quadratic_coef.detach().cpu().numpy())
plt.title("Weights")
plt.subplot(1, 2, 2)
plt.imshow(self.bm_net.quadratic_coef.grad.cpu().numpy())
plt.title("Gradients")
plt.show()
optimizer.step()
scheduler.step()
# 输出与保存
self.saver.output_loss(
step, kl_divergence.item(), ncl.item(), obj.item()
)
if step % 10 == 0:
t_now = time.time()
self.saver.save_info(self.bm_net, save_path, step, t_now - t_start)
pool.close()
pool.join()
5. 保存与加载模型#
Saver 类用于在模型训练过程中持久化关键信息。
它提供两个功能:
一是将当前模型以 PyTorch 格式定期保存为带步数编号的文件,便于后续加载或断点续训;
二是将每一步的损失值追加写入 loss.txt 日志文件,支持训练过程的可视化分析与性能追踪。
class Saver:
"""用于保存信息"""
def __init__(self, log_path="./log"):
"""初始化"""
self.log_path = log_path
if not os.path.exists(log_path):
os.makedirs(log_path)
def save_info(self, model, save_path, output_i, time):
"""保存模型等信息
Args:
model (Model): 构造模型相关参数
bias_path (str): 一次项系数的路径
interation_path (str): 二次项系数的路径
t_run (float): 计算运行时间
"""
save_path = os.path.join(save_path, f"rbm_model{output_i}.pth")
print(f"time: {time}, save_path: {save_path}")
torch.save(model, save_path)
def output_loss(self, output_i, kl_div, ncl, func):
"""输出loss
Args:
model (Model): 构造模型相关参数
pr_vi (float): graph_out_hidden相关概率
pr_v (float): graph_hidden相关概率
output_i (int): 计算步数
"""
print(f"step:{output_i}, kl_div:{kl_div}, ncl:{ncl}, cost:{func}")
with open(os.path.join(self.log_path, "loss.txt"), "a", encoding="utf8") as f:
f.write(f"step:{output_i}, kl_div:{kl_div}, ncl:{ncl}, cost:{func}\n")